Wer heute komplexe Geschäftsprozesse, Datenströme oder Kundenanfragen automatisieren möchte, greift fast automatisch zu den bekannten Cloud-Plattformen. Doch mit jedem Klick, jedem Workflow und jedem übermittelten Datensatz wächst die Unberechenbarkeit. Wir begeben uns in die Abhängigkeit von proprietären Systemen, deren Preisgestaltung, Datenschutzrichtlinien und Ausfallrisiken wir nicht kontrollieren können.
Wahre digitale Souveränität beginnt dort, wo wir die Infrastruktur wieder selbst besitzen. Genau hier setzt n8n als selbst gehostete Variante an – und entfaltet in Kombination mit lokalen KI-Servern eine völlig neue Dynamik für Entwickler und Unternehmen.
Was ist n8n und wie nutzt man es für seine Zwecke?
n8n ist im Kern eine visuelle Plattform zur Workflow-Automatisierung. Statt starre Code-Wüsten für jede API-Anbindung zu schreiben, verbindet man über eine intuitive, Node-basierte Oberfläche verschiedene Dienste, Datenbanken und Webhooks miteinander. Das Prinzip ist denkbar flexibel: Ein Trigger (z. B. der Eingang einer E-Mail, ein neuer Webhook-Call oder ein CRON-Job) stößt eine Kette von nachgelagerten Nodes an, die Daten transformieren, filtern oder an andere APIs weiterleiten.
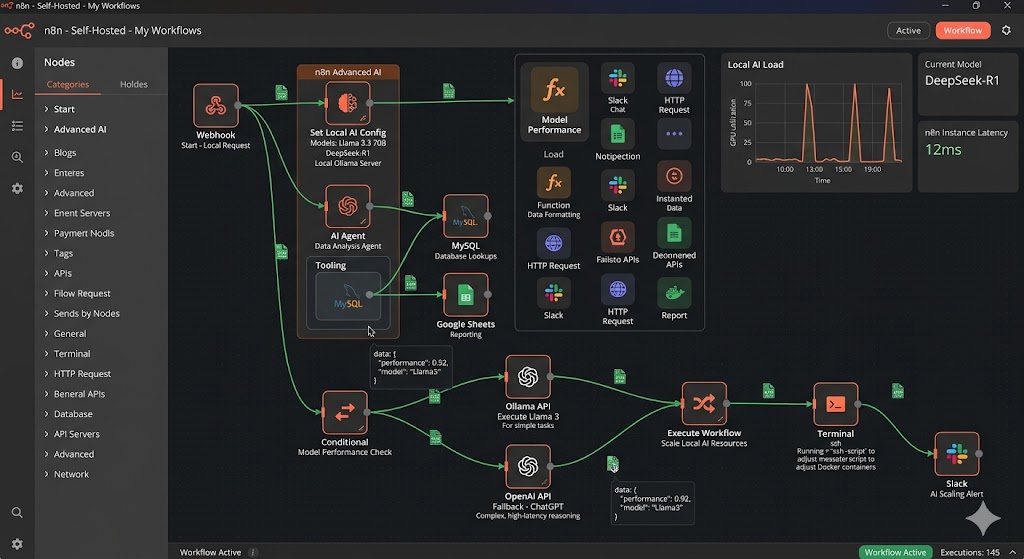
Das Spektrum reicht von der einfachen Synchronisation zwischen einem CRM und dem internen Projektmanagement bis hin zu hochgradig komplexen, fehlerbeseitigenden Daten-Pipelines. Der entscheidende Unterschied zur Cloud-Version: Wer n8n auf dem eigenen Server betreibt (etwa via Docker), bricht aus dem Korsett künstlicher Limits aus. Es gibt keine Paywall, die nach einer bestimmten Anzahl von Workflow-Schritten greift, und keine gedeckelten Ausführungen pro Monat. Die Plattform läuft nach den eigenen Regeln, skaliert mit der bereitgestellten Hardware und hält sensible Unternehmensdaten exakt dort, wo sie hingehören – in der eigenen, geschützten Infrastruktur.
Die Evolution: Advanced AI im eigenen Rechenzentrum
Das Zusammenspiel aus Automatisierung und Künstlicher Intelligenz erreicht jedoch erst dann das nächste Level, wenn auch das Gehirn der Workflows – das Large Language Model (LLM) – selbst verwaltet wird. n8n bringt dafür native, mächtige Advanced-AI-Komponenten mit. Sie erlauben es, Sprachmodelle nicht nur als passive Chatpartner zu nutzen, sondern als aktive Agenten direkt in die Datenströme einzubinden.
Ein lokaler KI-Server, beispielsweise betrieben über Ollama, bricht dabei die Dominanz der großen Tech-Giganten. Wenn Daten für die KI-Verarbeitung nicht mehr an externe APIs im Ausland gesendet werden müssen, fällt die letzte regulatorische und technologische Hürde. Damit wird der Einsatz von KI in hochsensiblen Bereichen wie dem Finanzwesen, der internen Softwareentwicklung, der Rechtsberatung oder dem Gesundheitswesen überhaupt erst DSGVO-konform machbar.
Der Performance-Vergleich: Lokale Ollama-Modelle vs. Cloud-Giganten
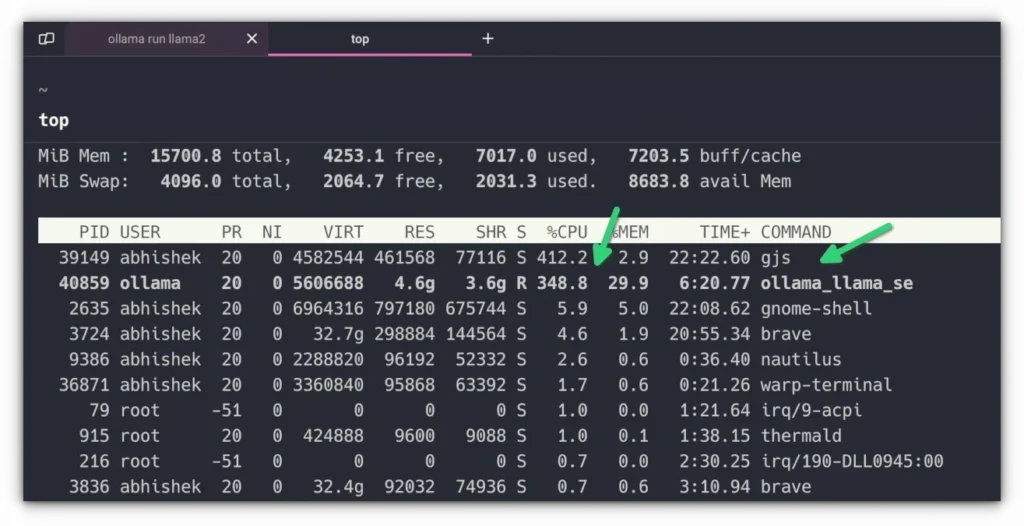
Doch wie schlägt sich die Open-Source-Welt im direkten Performance-Vergleich? Wer eine Flotte von lokalen Spitzenmodellen über Ollama betreibt, stellt schnell fest, dass die pauschale Aussage „Kommerziell ist immer besser“ längst überholt ist. Im täglichen Einsatz zeigt sich ein hochdifferenziertes Bild zwischen den führenden lokalen Modellen und Cloud-Diensten wie ChatGPT (GPT-4o), Claude 3.5 Sonnet oder Gemini 1.5 Pro.
1. Latenz und Durchsatz (Time-to-First-Token)
In der Kategorie der reinen Ausführungsgeschwindigkeit ziehen spezialisierte und optimal quantisierte lokale Modelle auf potenter Hardware – wie etwa einem modernen Mac Studio mit Unified Memory oder dedizierten Linux-Workstations mit RTX-Grafikkarten – oft an der Cloud-Konkurrenz vorbei.
Während Anfragen an ChatGPT, Claude oder Gemini den Umweg über das Internet, Lastverteiler und oft überlastete Rechen zentren nehmen müssen, antworten lokale Modelle wie ein Qwen2.5-Coder (z.B. in der 32B-Variante) oder ein kompaktes Gemma 2 bei Entwicklungs- und Automatisierungsaufgaben fast verzögerungsfrei. Für Batch-Verarbeitungen, bei denen tausende Datenzeilen nacheinander bereinigt werden müssen, ist der lokale Durchsatz ohne API-Drosselung unschlagbar.
2. Logische Tiefe und Tool Calling innerhalb von n8n
Betrachtet man die Fähigkeit zur komplexen Werkzeugnutzung (Funktionsaufrufe ausführen und JSON-Strukturen fehlerfrei einhalten), halten die Spitzenmodelle der Open-Weight-Szene mühelos Schritt.
- Ein über Ollama decentralisiertes DeepSeek-R1 (in den 32B oder 70B Destillationen) brilliert durch tiefes, logisches Denken (Chain-of-Thought) vor der eigentlichen Ausgabe.
- Llama 3.3 (70B) zeigt eine extrem stringente Einhaltung von System-Prompts und eine fehlerfreie Übergabe von strukturierten Daten an die nächsten n8n-Nodes.
Sie erreichen in diesen Kernkompetenzen der intelligenten Automatisierung ein Niveau, das den geschlossenen Flaggschiffen der kommerziellen Anbieter in nichts nachsteht und diese bei spezialisierten Aufgaben im Code-Verständnis manchmal sogar übertrifft.
3. Wo die Cloud noch die Nase vorn hat
Der wahre Vorteil der Cloud-Giganten schrumpft zunehmend auf ein spezifisches Szenario zusammen: Gigantische Kontextfenster im Megatoken-Bereich, wie sie vor allem Gemini bietet. Wer synchron ganze Dokumentenbibliotheken oder stundenlanges Videomaterial in einem einzigen Prompt durchwühlen möchte, stößt lokal aufgrund des immensen VRAM-Bedarfs schnell an physische Hardware-Grenzen.
Fazit: Souveränität ist produktiv einsatzbereit
Für die tägliche Praxis der intelligenten Prozessautomatisierung innerhalb von n8n – sei es das Klassifizieren von E-Mails, das Extrahieren von Metadaten aus Rechnungen, autonomes Scripting oder das intelligente Steuern von Systemen – bietet die Kombination aus selbst gehostetem n8n und einem lokalen Ollama-Server die perfekte Balance. Sie liefert kompromisslose Geschwindigkeit, ebenbürtige logische Präzision und das unbezahlbare Privileg, die absolute Kontrolle über die eigenen Daten und Prozesse zu behalten. Digitale Souveränität ist keine Utopie mehr – sie ist produktiver Standard.